





1.引言
博主曾发现了一个宝藏网站可以白嫖GPU算力,启智协作平台,每天运行一次云脑实例可以获得10积分,而积分就可以用来购买GPU算力,但是博主即将高考每天都很忙,可能就想不起来签到,于是我就像写个脚本然后把脚本扔挂机宝上让他自己跑,我就不用管了,于是说开始就开始。
2.开始实现
2.1实现思路
我的大致思路是使用Python的requests库模拟我的浏览器向云脑实例申请接口发一个请求的数据包,等积分到手后为不浪费平台资源再向停止云脑实例的接口再发一个数据包用来停止云脑任务。
2.2开始抓包
打开burpsuite,点击代理,打开内置浏览器
访问启智的主页,注册或者登录一个账号,并进入到云脑实例的页面。
这里选择英伟达GPU,然后选0*V100的纯cpu资源,这个资源是免费的,镜像随意选择,然后点击最下面绿色的创建,等待创建完成。
等云脑状态显示为running时,我们先停止该资源。

然后回到Burpsuite,把拦截打开,此时再回到openi的云脑实例管理页面,点击”再次调试”,此时,Burpsuite抓到了数据包以及接口,如图。
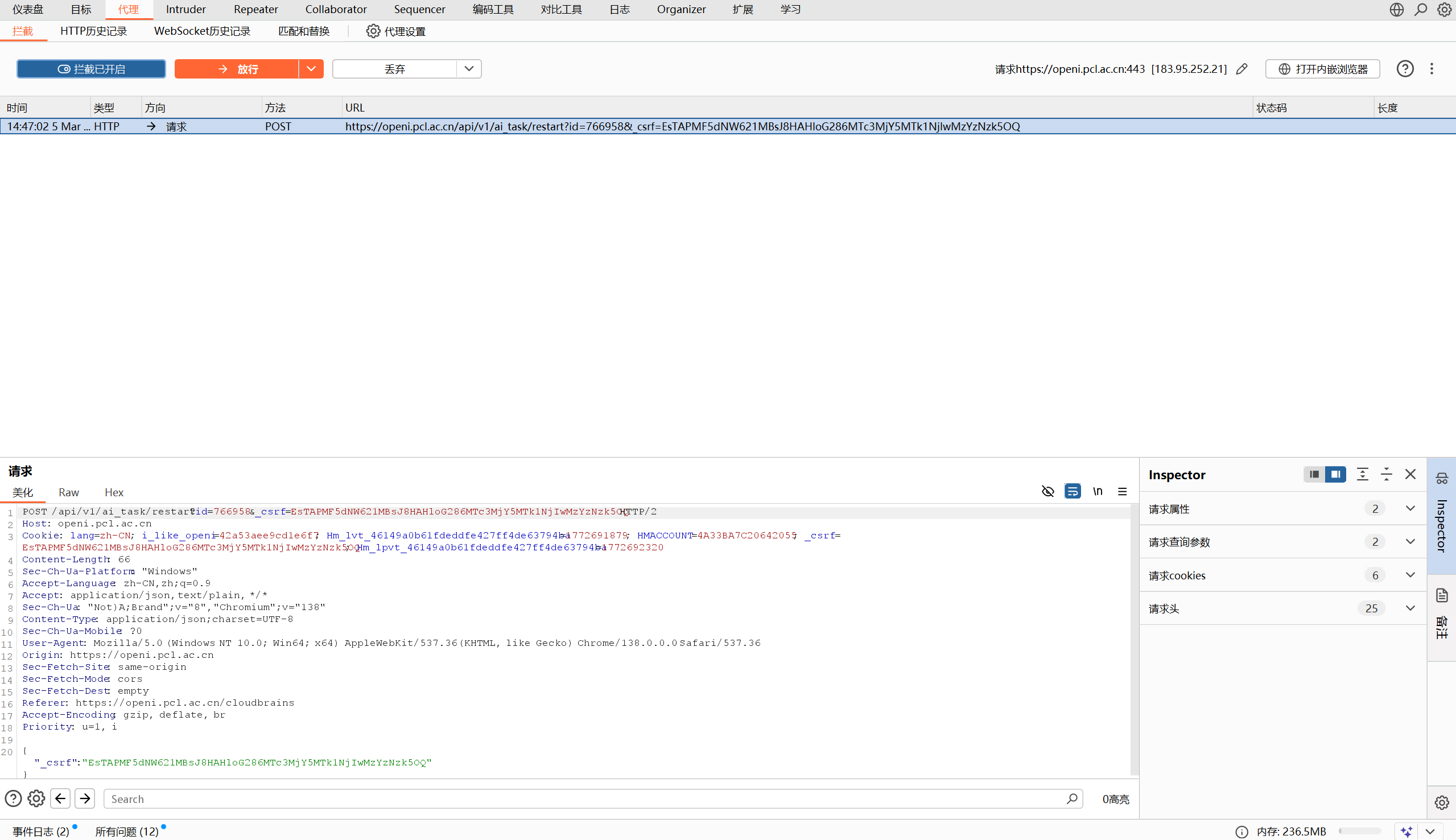
我们把抓到数据包复制出来
POST /api/v1/ai_task/restart?id=766958&_csrf=EsTAPMF5dNW621MBsJ8HAHloG286MTc3MjY5MTk1NjIwMzYzNzk5OQ HTTP/2Host: openi.pcl.ac.cnCookie: lang=zh-CN; i_like_openi=42a53aee9cd1e6f7; Hm_lvt_46149a0b61fdeddfe427ff4de63794ba=1772691879; HMACCOUNT=4A33BA7C20642055; _csrf=EsTAPMF5dNW621MBsJ8HAHloG286MTc3MjY5MTk1NjIwMzYzNzk5OQ; Hm_lpvt_46149a0b61fdeddfe427ff4de63794ba=1772692320Content-Length: 66Sec-Ch-Ua-Platform: "Windows"Accept-Language: zh-CN,zh;q=0.9Accept: application/json, text/plain, */*Sec-Ch-Ua: "Not)A;Brand";v="8", "Chromium";v="138"Content-Type: application/json;charset=UTF-8Sec-Ch-Ua-Mobile: ?0User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36Origin: https://openi.pcl.ac.cnSec-Fetch-Site: same-originSec-Fetch-Mode: corsSec-Fetch-Dest: emptyReferer: https://openi.pcl.ac.cn/cloudbrainsAccept-Encoding: gzip, deflate, brPriority: u=1, i
{"_csrf":"EsTAPMF5dNW621MBsJ8HAHloG286MTc3MjY5MTk1NjIwMzYzNzk5OQ"}2.3 核心参数提取
通过观察上述 HTTP 请求报文,我们可以分析出该数据包的核心要素:
- 请求方法:
POST - 目标接口:
/api/v1/ai_task/restart - 鉴权机制:观察到请求头中的
Cookie以及Content-Type: application/json,说明服务器不仅校验用户的登录状态,还要求以 JSON 格式提交数据。
尤其值得注意的是它的数据包中有一个csrf属性,这是用来防跨站攻击的。但是它的请求体 Payload 非常简单,只有一行 JSON 数据:
{ "_csrf": "EsTAPMF5dNW621MBsJ8HAHloG286MTc3MjY5MTk1NjIwMzYzNzk5OQ"}结论:在编写Python脚本时,我们需要获取到_csrf参数,以及然后链接后的restart?id=发送到接口/api/v1/ai_task/restart即可。
启动数据包逻辑分析完毕我们再抓一下关闭云脑实例数据包,以和启动抓包相同的方法抓到关闭云脑的数据包,如下。
POST /api/v1/ai_task/stop?id=766981&_csrf=EsTAPMF5dNW621MBsJ8HAHloG286MTc3MjY5MTk1NjIwMzYzNzk5OQ HTTP/2Host: openi.pcl.ac.cnCookie: lang=zh-CN; i_like_openi=42a53aee9cd1e6f7; Hm_lvt_46149a0b61fdeddfe427ff4de63794ba=1772691879; HMACCOUNT=4A33BA7C20642055; _csrf=EsTAPMF5dNW621MBsJ8HAHloG286MTc3MjY5MTk1NjIwMzYzNzk5OQ; Hm_lpvt_46149a0b61fdeddfe427ff4de63794ba=1772692320Content-Length: 66Sec-Ch-Ua-Platform: "Windows"Accept-Language: zh-CN,zh;q=0.9Accept: application/json, text/plain, */*Sec-Ch-Ua: "Not)A;Brand";v="8", "Chromium";v="138"Content-Type: application/json;charset=UTF-8Sec-Ch-Ua-Mobile: ?0User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36Origin: https://openi.pcl.ac.cnSec-Fetch-Site: same-originSec-Fetch-Mode: corsSec-Fetch-Dest: emptyReferer: https://openi.pcl.ac.cn/cloudbrainsAccept-Encoding: gzip, deflate, brPriority: u=1, i
{"_csrf":"EsTAPMF5dNW621MBsJ8HAHloG286MTc3MjY5MTk1NjIwMzYzNzk5OQ"} 发现启动和关闭的请求格式基本一致,那么分析清楚了启动的关闭的逻辑,接下来我们就需要寻找一下csrf和id后面的值如何获取,经过搜索我发现在网页的源代码中居然就存在csrf。
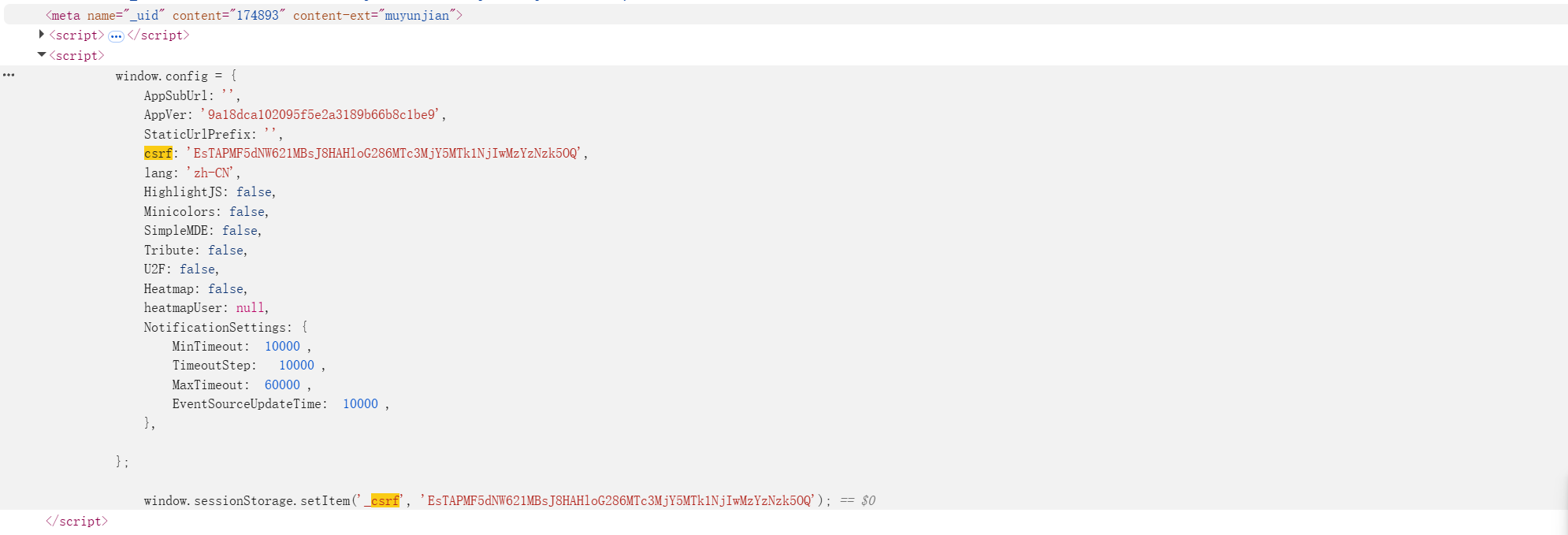
那这个就秒了,开始关注id属性,同样的搜索方法,我发现在发送启动和停止的请求时,在Response中居然会返回其id的值,并且每次发送启动的请求时id值为上次停止请求Response返回的id值,同时发送停止请求时也是同理。
 既然如此,那就好办了,再第一次时先通过网页抓包记录id,然后将id填入程序中,后续每次运行时都储存Response中的is值覆盖上一次值,下次执行时再调用上次存储的id值并再次覆写。
既然如此,那就好办了,再第一次时先通过网页抓包记录id,然后将id填入程序中,后续每次运行时都储存Response中的is值覆盖上一次值,下次执行时再调用上次存储的id值并再次覆写。
3. 开始编写程序
3.1 获取csrf值
对于这个csrf,我发现我每次登录都会分配给我一个,但是有时效限制,这又要牵扯到对前端js的加解密,在复杂了,我发现网页登录没有做人机验证,那我直接使用python的playwright库访问网页,提前填写好用户名和密码,在浏览器成功登录后获取网页源代码提取cookie和csrf。
from playwright.sync_api import sync_playwrightimport re
def get_auth_info(username, password): with sync_playwright() as p: #因为要放到无图形化界面的linux服务器所以要设置成无头模式 browser = p.chromium.launch(headless=True) page = browser.new_page()
page.goto("https://openi.pcl.ac.cn/user/login")
page.fill("input[name='user_name']", username) page.fill("input[name='password']", password) page.click("button[type='submit']")
page.wait_for_url("**/cloudbrains**", timeout=10000)
cookies = page.context.cookies() cookie_str = "; ".join([f"{c['name']}={c['value']}" for c in cookies])
html = page.content() csrf_match = re.search(r'name="csrf-token" content="(.*?)"', html) csrf_token = csrf_match.group(1) if csrf_match else None
browser.close() return cookie_str, csrf_token3.2 id值的获取
如上文所说,直接用一个with open方法将id存储在本地的文本文件中即可。
import os
ID_FILE = "task_id.txt"
def read_task_id(): if os.path.exists(ID_FILE): with open(ID_FILE, "r") as f: return f.read().strip() return "766958" # 如果文件不存在,填入你第一次抓包手动记录的初始 ID
def save_task_id(new_id): with open(ID_FILE, "w") as f: f.write(str(new_id))3.3 最终代码
import osimport reimport timeimport jsonimport requestsfrom playwright.sync_api import sync_playwright
ID_FILE = "task_id.txt"
def get_auth_info(username, password):
with sync_playwright() as p: browser = p.chromium.launch(headless=True) page = browser.new_page() page.goto("https://openi.pcl.ac.cn/user/login")
page.fill("input[name='user_name']", username) page.fill("input[name='password']", password) page.click("button[type='submit']")
# 等待页面跳转,确保登录成功 page.wait_for_url("**/cloudbrains**", timeout=10000)
# 获取 Cookies 并拼接成字符串 cookies = page.context.cookies() cookie_str = "; ".join([f"{c['name']}={c['value']}" for c in cookies])
# 从网页源码中正则匹配提取 csrf 值 html = page.content() csrf_match = re.search(r'name="csrf-token" content="(.*?)"', html) csrf_token = csrf_match.group(1) if csrf_match else None
browser.close() return cookie_str, csrf_token
def read_task_id(): """读取本地存储的上一次任务 ID""" if os.path.exists(ID_FILE): with open(ID_FILE, "r") as f: return f.read().strip() return "766958" # 如果文件不存在,填入你第一次抓包手动记录的初始 ID
def save_task_id(new_id): """将新的任务 ID 保存到本地""" with open(ID_FILE, "w") as f: f.write(str(new_id))
def send_wechat_push(title, content): """使用 PushPlus 发送微信推送""" token = "YOUR_PUSHPLUS_TOKEN" # 替换为你自己的 PushPlus Token url = "http://www.pushplus.plus/send" data = { "token": token, "title": title, "content": content } try: requests.post(url, json=data) print("[-] 微信推送发送成功!") except Exception as e: print(f"[x] 微信推送失败: {e}")
def main(): print("[-] 开始执行自动签到脚本...")
# 1. 登录并获取鉴权信息 username = "YOUR_USERNAME" # 替换为启智平台账号 password = "YOUR_PASSWORD" # 替换为启智平台密码 print("[-] 正在通过 Playwright 获取 Cookie 和 CSRF Token...") cookie_str, csrf_token = get_auth_info(username, password)
if not csrf_token: error_msg = "获取 CSRF Token 失败,请检查登录逻辑。" print(f"[x] {error_msg}") send_wechat_push("启智签到失败", error_msg) return
# 2. 读取任务 ID task_id = read_task_id() print(f"[-] 当前任务 ID: {task_id}")
# 3. 构造请求头 headers = { "Host": "openi.pcl.ac.cn", "Cookie": cookie_str, "Content-Type": "application/json;charset=UTF-8", "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36" }
payload = {"_csrf": csrf_token}
# 4. 发送启动请求 (Restart) restart_url = f"https://openi.pcl.ac.cn/api/v1/ai_task/restart?id={task_id}&_csrf={csrf_token}" print("[-] 正在发送启动实例请求...") res_start = requests.post(restart_url, headers=headers, data=json.dumps(payload))
if res_start.status_code == 200: print("[√] 实例启动成功!等待 60 秒以确保积分到账...") # 从响应中提取新的 ID new_start_id = res_start.json().get('id', task_id)
# 等待一段时间,让云脑运行一会拿到积分 time.sleep(60)
# 5. 发送停止请求 (Stop) stop_url = f"https://openi.pcl.ac.cn/api/v1/ai_task/stop?id={new_start_id}&_csrf={csrf_token}" print("[-] 积分已到手,正在发送停止实例请求释放资源...") res_stop = requests.post(stop_url, headers=headers, data=json.dumps(payload))
if res_stop.status_code == 200: print("[√] 实例停止成功!") final_id = res_stop.json().get('id', new_start_id)
# 6. 保存最终的 ID 供明天使用 save_task_id(final_id)
success_msg = f"新任务 ID ({final_id}) 已保存。今日10积分已到手!" print(f"[√] {success_msg}") send_wechat_push("启智签到成功", success_msg) else: error_msg = f"停止实例失败,状态码: {res_stop.status_code}" print(f"[x] {error_msg}") send_wechat_push("启智签到异常", error_msg) else: error_msg = f"启动实例失败,状态码: {res_start.status_code}" print(f"[x] {error_msg}") send_wechat_push("启智签到失败", error_msg)
if __name__ == "__main__": main()脚本写完后直接扔到服务器上每天定时去跑就行了,就不用管他了。如果想知道进度的话可以去网上找一个免费的api微信公众号推送,每天运行完成后使用公众号将结果推送至微信,这样就不用管它可以安心备考了!ヽ(✿゚▽゚)ノ
4. 总结
这次的逆向工程实战虽然针对的只是一个简单的 API 接口,但麻雀虽小五脏俱全。从使用 Burp Suite 拦截分析 HTTP 报文,到准确提取出 _csrf 和 id 两个核心动态参数,再到利用 Python 和 Playwright 框架巧妙绕过繁琐的前端 JS 加密,最终实现全自动化的请求闭环。
部分信息可能已经过时